
캐시란 시간이 많이 걸리는 연산을 미리 계산해놓고 빨리 가져다 쓰거나, DB 부하를 줄이기 위해 Read 가 많이 발생하는 데이터를 캐싱해놓고 빨리 가져다 쓰는 기법이다.(write 를 위한 캐시 또한 존재) 그리고 캐시를 하는 위치에 따라 로컬캐시, 분산캐시로 나눌수 있는데 로컬캐시의 경우 자바의 ehcache 가 대표적이며 속도는 로컬캐시가 가장 빠르다. 왜냐하면 분산 캐시의 경우 별도의 서버로 외부에서 작동하기 때문에 네트워크 통신같은 오버헤드가 필연적으로 발생한다.
그럼 가장 빠른 로컬 캐시가 좋으니 무조건 로컬 캐시를 사용하면 되지 않을까? 서비스의 규모가 작고 모놀리틱하게 서버 한대로만 운영한다면 초창기엔 로컬캐시만 사용해도 문제가 없을수도 있다. 하지만 서비스가 성장함과 동시에 서버 한대로는 운영이 점점 힘들어지며 가용성 문제도 발생한다. 그리고 여러 서버에서 로컬 캐시를 사용하게 되는 경우 각 서버마다 캐싱한 데이터가 달라 동기화 이슈가 발생하는데 이는 stick session 이나 session clustering 을 통해 어느정도 해결을 할순 있지만 규모가 커질수록 이들의 단점 또한 더욱더 부각될수 있다.
그래서 로컬캐시 보다 좀더 안정적이고 빠른 읽기 작업 효과를 가질수 있는 방안으로 인메모리 DB 를 사용 한다. 그리고 이렇게 메모리를 통해 데이터 처리를 하는 경우 디스크보다 I/O 성능이 수십, 수백배 뛰어나기 때문에 디스크보다 더 빠른 속도로 처리할수 있다. 하지만 이를 너무 믿고 캐시에 매우 의존적이기 보단 캐시가 다운됐을때 DB 가 어느정도 감당 가능하게끔 적절한 스펙의 DB 서버 또한 필요하다. 그리고 모든 캐시가 날아가는게 아니라 여러 캐시중 단 하나의 캐시만 날아가더라도 수많은 요청이 몰릴수 있는데 hit 가 엄청 많은 인기있는 데이터가 날아갔을 경우가 그렇다. 이렇게 갑작스렇게 수많은 요청이 들어오는걸 Thundering herd 라 부른다.
위와 같이 캐시가 날아가는 경우 이는 곧 DB 에 많은 부담을 줄 수밖에 없다. 이에 대한 안전장치로 2중 3중 캐시 다중화를 하여 안전성을 높일수 있다. redis 클러스터링이 어떻게 작동하는지 보면 이에 대한 구성이 아주 잘 되어 있다. 그리고 캐시와 DB 사이에서 데이터의 정합성 문제가 발생할수도 있는데 이는 상황에 맞는 적절한 읽기, 쓰기 전략을 통해 잘 관리하여야 한다.
그럼 아래에선 캐싱 전략에 대해 알아보도록 하자.
캐시 읽기 전략
- Cache Aside (Look Aside)
- Read Through
Cache Aside (Look Aside)
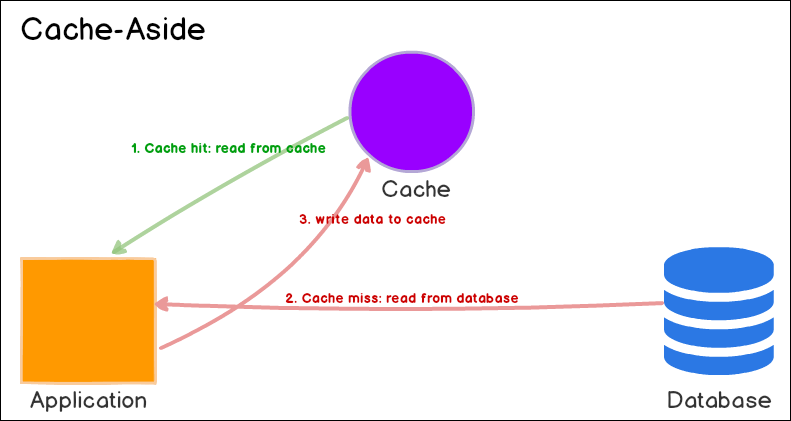
- 캐싱된 데이터가 있는지 확인하고 있다면 읽어온다.
- 캐싱된 데이터가 없다면 DB 로부터 가져온다.
- DB 로 부터 가져온 데이터를 캐싱한다.
- 읽기 작업이 많은 경우 적합
- 캐시와 DB 가 분리되어 운영되기 때문에 장애 대비 구성이 되어있다. (캐시가 안되어 있을경우 DB 로부터 읽기작업)
- 캐시가 되어 있지 않은 데이터에 대해 순간적으로 많은 요청(Thundering herd)이 몰릴 경우 DB 에 많은 부하가 생길수도 있음
- 초기에 캐싱된 데이터가 없다면 DB 에 많은 부담이 될수도 있기 때문에 미리 데이터를 캐싱해놓는 방법도 있음 (Cache Warming)
Read Through
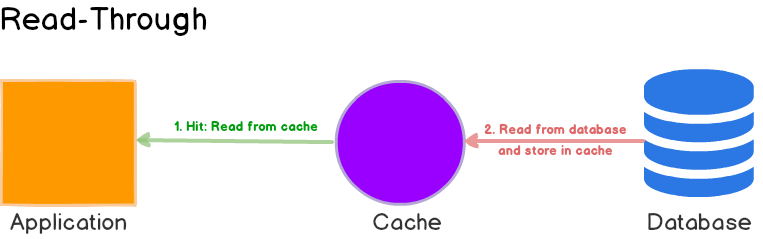
- 캐싱된 데이터가 있는지 확인하고 있다면 읽어온다.
- 캐싱된 데이터가 없다면 DB 로부터 데이터를 가져와 캐싱한다.
- Cache Aside 의 특징과 동일
- 특징은 위 Cache Aside 와 똑같지만 2가지 큰 차이점이 있다.
- Cache Aside 같은 경우 어플리케이션 서버가 데이터를 디비로부터 가져오고 캐싱을 담당하지만, Read Through 의 경우 라이브러리나 stand-alone 한 캐시 프로바이더가 담당한다.
- Cache Aside 와 다르게 Read Through 는 디비와 데이터가 달라질수 없다 (디비에 있는 데이터를 그대로 캐싱하기 때문에 어플리케이션 서버에서 디비의 데이터를 가져와 컨버팅 할수있는 Cache Aside 에 비해 유연성이 좀 떨어짐)
캐시 쓰기 전략
- Write Through
- Write Around
- Write Back
Write Through
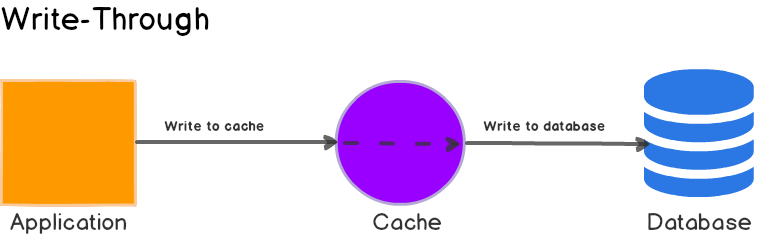
- 어플리케이션 서버 -> 캐시 저장소에 데이터 캐싱
- 캐시 저장소에 저장된 데이터를 DB 에도 저장한다 (이때 주체는 어플리케이션 서버가 아니라 캐시 저장소이다.)
이에 대한 예시로 AWS DAX 가 있다.

- write 발생시, 어플리케이션 서버 -> 캐시 저장소 -> DB 이렇게 통신이 이루어지기 때문에 쓰기 지연속도가 상대적으로 느려질수밖에 없다. 하지만 이렇게 할시 장점은 캐시와 DB 의 데이터가 일치하여 데이터 정합성을 만족할수 있다.
- Read Through 와 같이 사용할시 Read Through 의 특징인 빠른 읽기처리가 가능하다.
Write Around
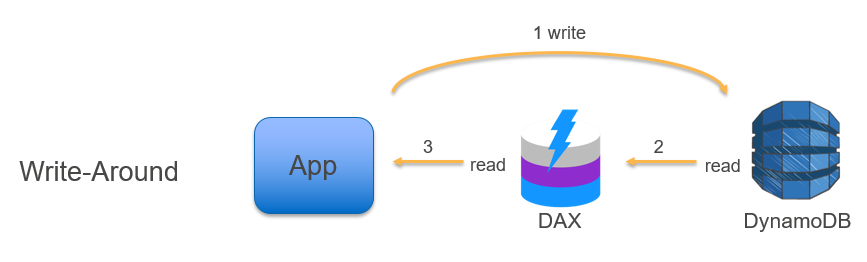
- Wrtie 시 캐시는 스킵하고 DB 에만 저장한다.
- 3. read 가 발생한 경우에 캐시 저장소에 데이터를 넣는다. (read-through or cache-aside)
write 가 한번만 쓰이는 경우, 위와 같이 읽기가 발생하는 데이터만 따로 캐싱을 하여 처리하면 hit 될 확률이 높은 데이터만 캐시 저장소에 저장되기 때문에 효율적인 사용이 가능 할 것이다.
Write Back (Wrtie Behind)
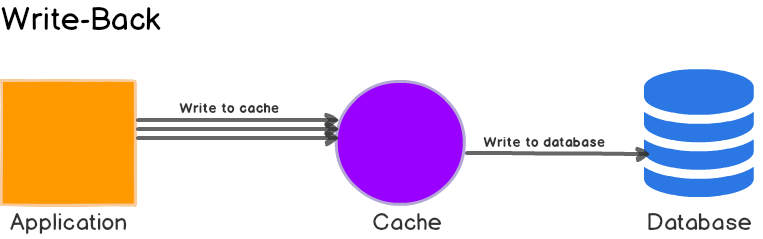
- Write 시 cache 저장소에 저장한다.
- write through 와의 차이점은 모든 write 에 대해 Cache 저장소와 DB 를 동기화 하여 저장하지 않고, 배치성 작업으로 DB와 싱크를 맞춘다.
- 어플리케이션 서버 입장에선 write 작업이 엄청 빠르다 (캐시 저장소에만 저장하기 때문)
- write-heavy 한 작업에 적합하다.
- read through 와 같이 사용하기에 적합하다.
- DB 장애에 대하여 복원력이 있다.
- DB 의 I/O 부하를 덜어줄수 있다. DB 같은 경우 디스크 I/O 가 엄청 많이 발생하여 과부하가 오면 디스크 I/O에 한계가 온다. (이런 경우 데이터 유실이 일어날수도 있음)
- 큰 단점은 cache 저장소에 장애가 일어날 경우 데이터가 영구적으로 유실될수도 있다.
참조
- https://codeahoy.com/2017/08/11/caching-strategies-and-how-to-choose-the-right-one/
- https://aws.amazon.com/blogs/database/amazon-dynamodb-accelerator-dax-a-read-throughwrite-through-cache-for-dynamodb/
- https://inpa.tistory.com/entry/REDIS-%F0%9F%93%9A-%EC%BA%90%EC%8B%9CCache-%EC%84%A4%EA%B3%84-%EC%A0%84%EB%9E%B5-%EC%A7%80%EC%B9%A8-%EC%B4%9D%EC%A0%95%EB%A6%AC#Look_Aside_%ED%8C%A8%ED%84%B4
'IT > 이것저것' 카테고리의 다른 글
| [유니코드 정규화] 같은 글자가 중복으로 저장되거나 검색에서 누락 된다면 유니코드를 의심해보자 (0) | 2024.02.21 |
|---|---|
| [ChatGPT] ChatGPT 더 잘 쓰는 법 prompt 패턴 (2) | 2023.11.13 |
| [카카오 로그인 연동] 카카오 로그인 연동 에러 해결방법 Admin Settings Issue (KOE101) (1) | 2023.01.21 |
| [PG] 나이스페이, 토스, 카카오페이 서비스 장애 발생시 처리 방법 (0) | 2023.01.17 |
| [jetbrains] phpstorm, intellij 개발시 유용한 단축키 (0) | 2023.01.02 |